苹果智能研究团队发布了一系列新学术论文,致力于提升AI个性化能力并解析错误产生机制。
尽管业界普遍认为苹果在AI领域落后,但其研究人员持续发表的论文已超越产品范畴,直指影响所有AI工具的核心问题。该公司多年来的研究在最新论文中聚焦于AI缺陷及如何预防不良行为。
最新发布的八篇论文延续了这一研究方向,同时公开了2024年”以人为中心机器学习”研讨会的完整系列演讲视频。
AI基准测试与错误识别
其中一篇论文提出了”大规模多任务代理理解基准”(MMAU),该系统通过五大核心能力评估不同大语言模型:
苹果表示MMAU基准包含”20项精心设计的任务,涵盖3000多个独立提示”,号称是目前最全面的大语言模型评估体系。
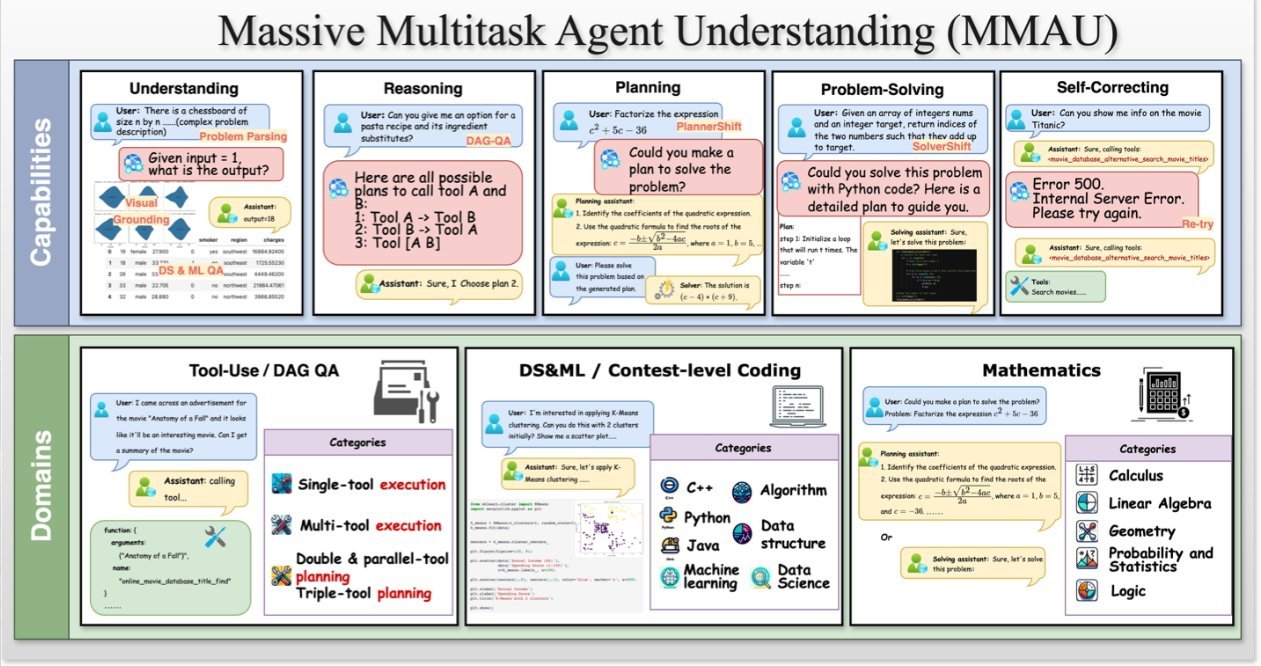
“MMAU不仅能揭示大语言模型代理的能力边界,更能增强其性能的可解释性。”苹果在论文中强调。
该研究旨在通过定位错误根源实现改进。苹果指出现有评估方法模糊了各类故障间的区别,而MMAU基准比现有方案更易操作。
完整论文详见康奈尔大学研究文献库。
AI个性化与对话学习
苹果认为当前大语言模型的个性化程度不足,例如缺乏持续记忆对话的能力。现有个性化方案仅聚焦于”插入用户偏好碎片信息”。
为此苹果提出”大语言模型用户对话学习管道”(PLUM),通过提取对话中的问答对构建机制,将历史对话知识注入大语言模型。
点击查阅完整论文。
大语言模型的外部验证
苹果指出,大语言模型对措辞调整极其敏感:”已观察到AI标注器存在多种偏差倾向”。但人类判断也易受”回答确定性表述”的影响——AI常以绝对口吻输出结果,直到被再次询问才承认错误。
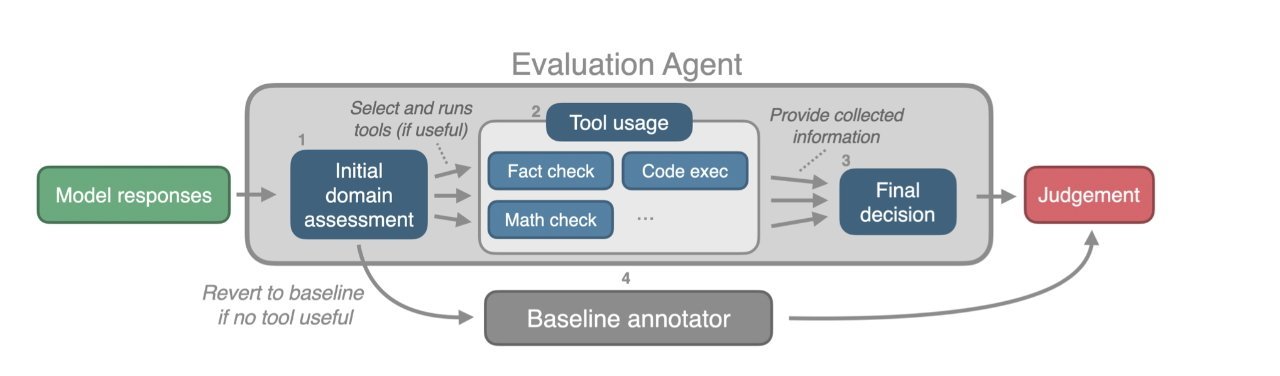
在《外部验证工具能否提升LLM作为评判者的标注质量?》论文中,苹果尝试通过”基于网络搜索和代码执行的外部验证工具”优化结果,但发现该方法仅能”经常而非绝对”产生更好效果。
点击查阅完整论文。
苹果持续亮相AI学术会议
除论文外,苹果还发布了2024年研讨会的八段演讲视频(10-38分钟不等),主题涵盖AI界面设计等方向。研究人员将持续参与学术活动,将于2025年7月27日至8月1日在维也纳举办的国际计算语言学协会(ACL)年会上展示18项最新研究。
具体议程详见苹果机器学习官网。