苹果研究团队持续深耕多模态大语言模型(MLLM),最新研究探索它们在图像生成、图像理解以及结合裁剪图像进行多轮网页搜索的强大能力。
随着 iOS 18 的发布,苹果已经让 iPhone 可以在本地 AI 模型的加持下直接生成图像。Image Playground 功能可以离线创作几乎任何事物的卡通风格照片,无需联网。
如今,苹果通过最新研究继续推进图像相关技术,深入探索多模态大模型如何理解、生成和使用图像。
在 2026 年 1 月公布的多篇研究论文中,苹果发布了题为《DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search》的论文。该研究可在苹果机器学习研究博客上查看,重点探讨大模型如何利用图像和智能裁剪来进行网页搜索。
另一篇与图像 AI 相关的论文则详细介绍了一个既能根据文字生成图像、又能理解图像内容的多模态大模型。
以下是这些研究论文的核心亮点。
DeepMMSearch-R1 —— 图像智能裁剪如何让多模态大模型搜索更准
在介绍 DeepMMSearch-R1 之前,苹果研究人员首先指出了当前具备搜索功能的多模态大模型普遍存在的缺陷:它们常常给出错误信息,甚至完全无法回答。
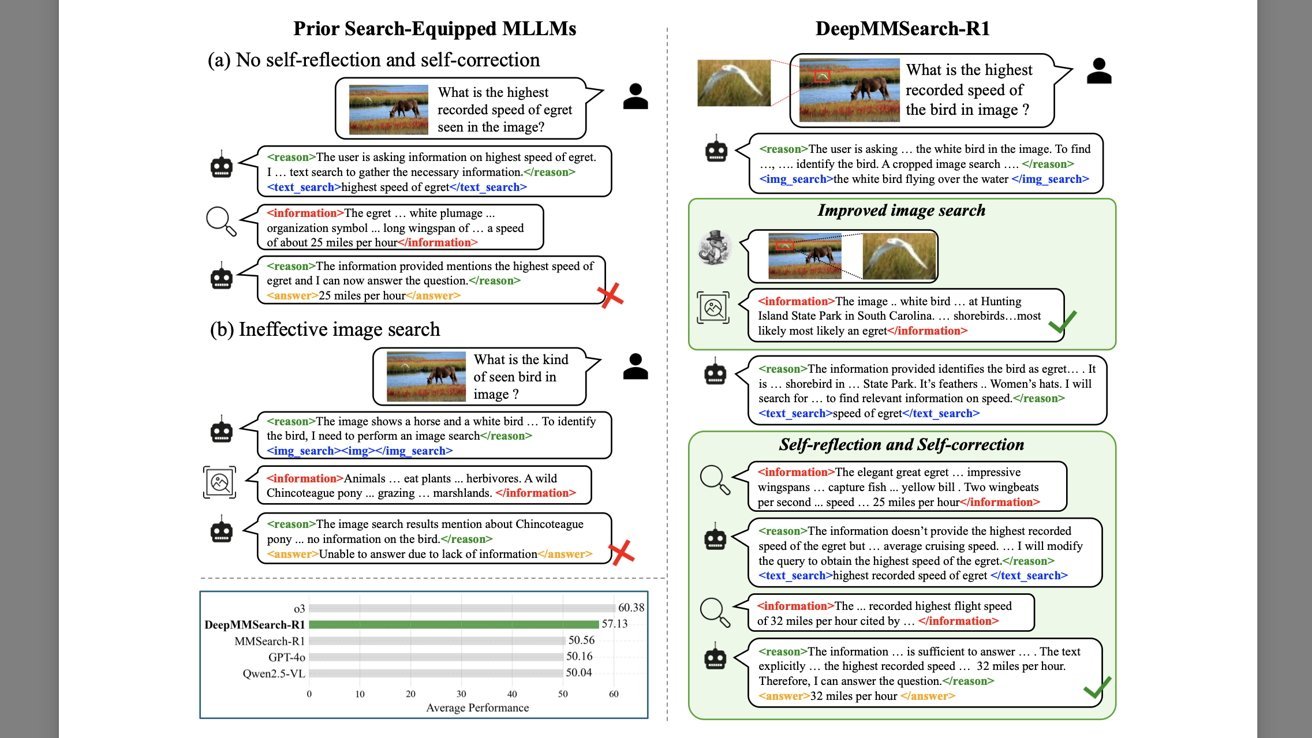
苹果的 AI 模型可以智能裁剪图像,并将其用于图像搜索和文本网页搜索。
研究通过两个关于“白鹭(egret)”的例子进行了生动说明。
当被问及“白鹭的最高速度是多少”时,一些大模型会错误地报出平均速度,因为它们只找到了同时包含“speed”和“egret”的文本,就直接采用了错误答案。
第二个例子中,给模型一张马的照片,左上角有一只小鸟。当询问照片里的鸟是什么种类时,模型直接进行图像搜索却一无所获,最终无法给出答案。
苹果的解决方案是:让多模态大模型具备按需裁剪图像的能力,并在给出最终答案前进行校正或二次验证。
回到白鹭的例子,DeepMMSearch-R1 拿到同一张带有马和白鹭的图片,被问到照片中鸟的最高速度是多少。
模型首先自动裁剪图像,只保留鸟的部分,然后进行图像搜索,确认是白鹭。随后它再进行网页搜索,并确保结果反映的是“最高速度”而非其他数值。
简单来说,DeepMMSearch-R1 包含三大核心工具:
- 文本搜索工具 —— 让模型获取网页上的最新事实知识
- 图像定位(grounding)工具 —— 必要时对图像进行精准裁剪
- 图像搜索工具 —— 根据完整或裁剪后的图像收集网页标题、描述等内容
该模型采用两阶段训练方式:“先进行监督微调(SFT),再进行在线强化学习(RL)”。SFT 防止模型无意义地乱裁剪图像,RL 则让工具使用变得更加高效精准。

苹果研究团队成功让多模态大模型只在真正需要时才使用裁剪工具。
测试结果显示,DeepMMSearch-R1 “大幅超越了传统的 RAG 流程和基于提示的搜索代理基准”。
研究人员认为:“DeepMMSearch-R1 是现实世界多模态信息获取 AI 的重要进步,未来在网页智能体、教育和数字助理领域都有广阔应用前景。”
如果说 DeepMMSearch-R1 聚焦于搜索,那么另一项研究则探索多模态大模型如何同时处理和创作图像,以及是否还存在提升空间。
Manzano —— 真正“无偏科”的多模态大模型:既能看懂又能画图
题为《MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer》的论文,介绍了一个在图像理解和图像生成两项能力上完全不偏科的多模态大模型。
Manzano 大模型在理解、编辑和生成图像方面均无明显短板。
Manzano 是一个采用自回归(AR)方式统一处理理解与生成任务的多模态大语言模型。
研究人员承认 GPT-4o 等现有模型的强大,但也指出目前大多数统一多模态模型都倾向于偏重图像生成或图像理解中的某一项,不可避免地带来性能折衷。
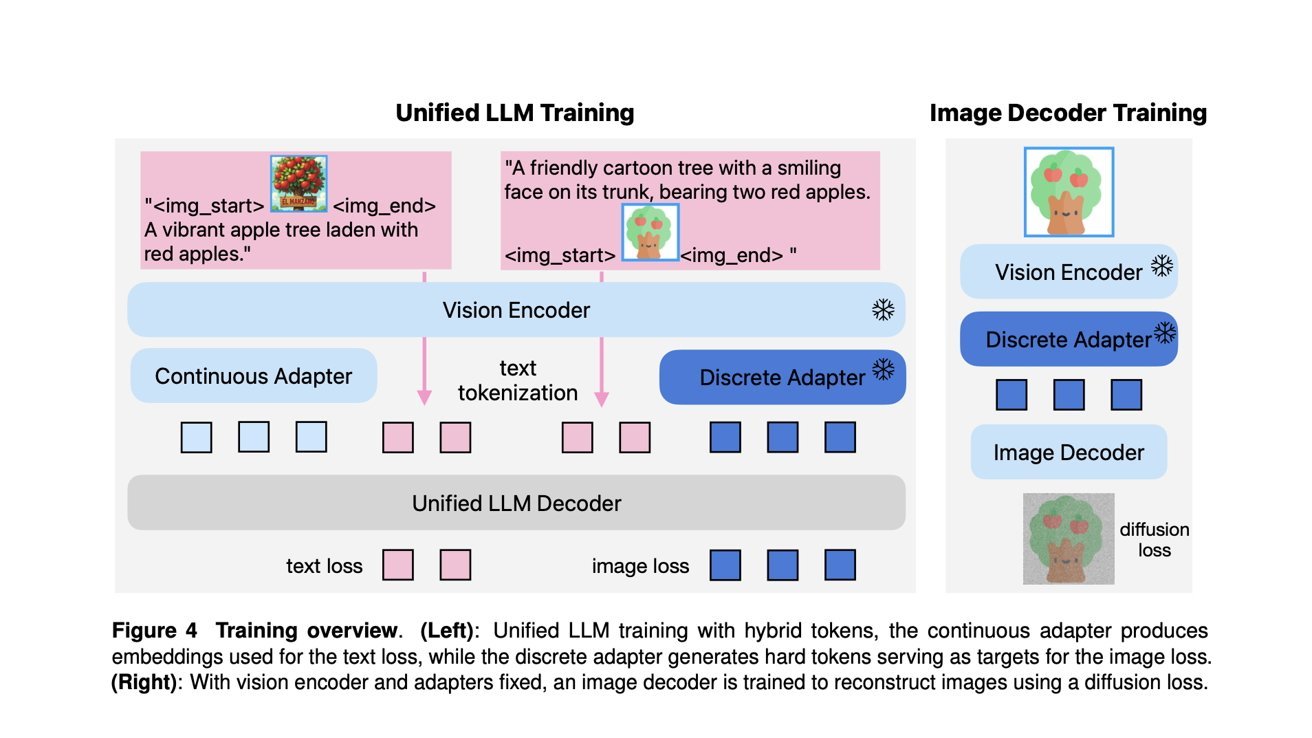
苹果团队选择了与 GPT-4o 不同的路线:“我们没有使用独立的理解和生成分词器,而是引入了统一的语义分词器,同时产生用于理解任务的连续特征和用于生成任务的量化特征。”
论文强调,这一策略“大幅缓解了常见的任务冲突问题”。
Manzano 由三大核心模块构成:
- 统一的共享视觉编码器/分词器,配备连续适配器(用于理解)和离散适配器(用于生成)
- 大语言模型解码器,接收文本 token 和/或连续图像嵌入,自回归地从联合词汇表中预测下一个图像或文本 token
- 图像解码器,将预测的图像 token 渲染成像素图像
前两个组件同时服务于图像理解与生成,而图像解码器则负责利用高斯噪声真正生成图像。
这种架构让苹果团队得以使用联合训练配方,让 Manzano 同时学习图像理解和图像生成。它在纯文本、图文交错、图生文、文生图等多种数据上进行训练。

更大规模的 LLM 解码器能显著提升 Manzano 性能。
论文指出,Manzano 在理解和生成两类任务上均达到“当前最佳水平”。团队测试了 300M、1B、3B 和 30B 等不同规模的 LLM 解码器版本,规模越大通常表现越好。
即便在紧凑的 300M 规模下,“采用我们混合分词器的统一大模型在几乎所有任务上都能媲美专用的单任务模型”。而 3B 和 30B 版本则“在多数指标上超越或匹敌其他最先进统一多模态大模型”。
Manzano 还能很好地处理“反常识、违反物理规律的提示”(例如“鸟在大象下面飞”),表现与 GPT-4o 和 Nano Banana 相当。其他例子还包括柯基举牌说“我不是柯基”。

Manzano 轻松应对违反物理常识的奇葩提示。
此外,Manzano 还具备强大的图像编辑能力,包括指令引导编辑、风格迁移、局部重绘(inpainting)、向外扩展(outpainting)和深度估计等。即便图像有缺失部分,它也能根据需求合理补全。
苹果研究团队最终得出结论:一个同时擅长图像生成与理解的统一多模态大模型,并不需要牺牲其中一项能力来换取另一项的优秀表现。
从应用角度看,未来 Siri 很有可能迎来更多强大的图像相关功能。预计 2026 年春季发布的 iOS 26.4 将为 Siri 带来基于 Google Gemini 的重大升级。