苹果对AI模型以及它们在空间计算上的应用兴趣丝毫没有减退,尽管有人说Apple Vision Pro已经凉了。
2026年4月的时候,有传闻称Apple Vision Pro彻底失败,所以永远不会有下一代产品。虽然这个说法听起来一直不太靠谱,但现在看来确实站不住脚。
即便公司的Vision Products Group有一些人事调整,但新一代Apple Vision Pro还是有希望的。苹果的AI研究表明,他们并没有放弃跟空间计算相关的项目。
相反,苹果机器学习博客最近发布的几篇新论文,探讨了大语言模型在手语标注、3D头部建模等方面的应用。研究人员还开发了一个新的基准测试系统,来评估大模型的空间功能智能。
给多模态大模型打造空间功能智能基准测试
这篇题为《从东西在哪里到它们是干什么的:多模态大模型的空间功能智能基准测试》的论文,提出了一套全新的测试和评分体系。

苹果研究团队开发了一个基准框架,专门测试多模态大模型的空间推理能力。图片来源:Apple
论文里提到,要让AI像人一样理解空间和物体,需要两种不同的结构:一种是捕捉物体布局和关系结构的空间表示,另一种是编码功能、可供性、用途以及上下文相关的功能表示。
简单说,多模态大模型既要懂空间的几何结构,也要明白里面物体的用途和位置。研究人员指出,现有的基准测试比如VSI-Bench,大多只考察前者,基本忽略了后者。
为此,他们开发了Spatial-Functional Intelligence Benchmark,简称SFI-Bench。这是一个基于视频的测试,包含134个室内视频扫描得到的1555个专家标注问题。
关于SFI-Bench具体考什么,论文讲得很清楚:
“除了空间认知,SFI-Bench还加入了功能和知识 grounding 的推理,考察模型是否理解场景中物体的用途、如何操作,以及如何诊断故障。”
换句话说,这个测试会问AI:物体是什么、在哪、怎么用、用来干嘛、坏了怎么修。

苹果AI研究团队测试了大模型对周围世界的理解程度。图片来源:Apple
这听起来有点熟悉,因为谷歌从2024年就开始有类似空间感知的工具了。在那年的I/O大会上,谷歌的AI模型能认出面前的留声机,还能给出维修建议。
实际应用中,SFI-Bench可以用来测试类似甚至更先进的大模型。测试例子包括:让模型找出柜子上同一品牌瓶子最多的那一组、取消洗衣机当前程序、电视遥控器是干什么的等等。
苹果研究人员用SFI-Bench测试了多个开源和商用模型。结果不出意外,谷歌Gemini 3.1 Pro综合表现最好,Gemini-3.1-Flash-Lite排第三,OpenAI的GPT-5.4-High位居第二。
不过论文也指出,“在所有模型中,全局条件计数成了主要瓶颈,暴露了组合和逻辑推理的持续短板。”
也就是说,目前大多数多模态大模型在空间记忆、功能知识整合,以及把感知和外部知识联系起来方面还是比较吃力。不过,有联网能力的模型表现明显好于纯离线模型。
对iOS来说,这可能意味着未来Siri会同时具备空间和上下文感知能力。这也合理,毕竟苹果已经跟谷歌合作做Apple Intelligence功能了。
至于什么时候上线、实际效果如何,还得等等看。
用AI模型辅助手语标注
另一篇论文《用手语模型自举手语标注》里,苹果研究人员探索了如何用AI来标注手语视频。
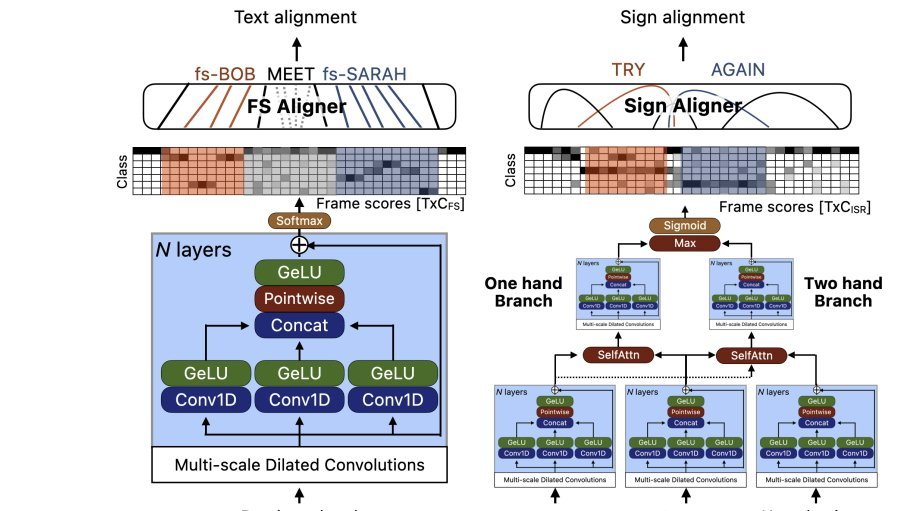
苹果研究团队探索用AI进行ASL(美国手语)标注。图片来源:Apple
他们开发了一个“伪标注流程”,输入手语视频和英文,输出带时间戳的、按可能性排序的标注,包括手势词、拼写词和手语分类器。
这样做的目的是大幅降低手动标注几百小时手语视频的时间和成本。他们还构建了简单但有效的手指拼写和孤立手语识别模型,在FSBoard数据集上达到6.7% CER,在ASL Citizen数据集上达到74% top-1准确率,属于目前领先水平。
研究人员手动做了近500条英文到手语词汇的标注,并通过反向翻译、手动验证和伪标注,对超过300小时的ASL STEM Wiki和7.5小时的FLEURS-ASL进行了验证。
测试时,他们给Claude Sonnet 4.5一个从手语到英文的提示,让它把手动标注的ASL STEM Wiki翻译成参考英文文本。
论文指出,“错误主要出现在没有手指拼写的句子中。”虽然还有很多工作要做,但研究人员表示,他们的手指拼写识别和孤立手语识别模型只需要普通GPU就能训练,也能用来进一步优化伪标注流程。
苹果为什么研究这个?可能跟传闻中带摄像头的AirPods有关。或许他们计划把实时翻译功能扩展到手语支持。
从多视角捕捉重建高质量3D高斯头部模型
另一篇论文《Large-Scale High-Quality 3D Gaussian Head Reconstruction from Multi-View Captures》研究了如何用AI从图像生成头部模型。
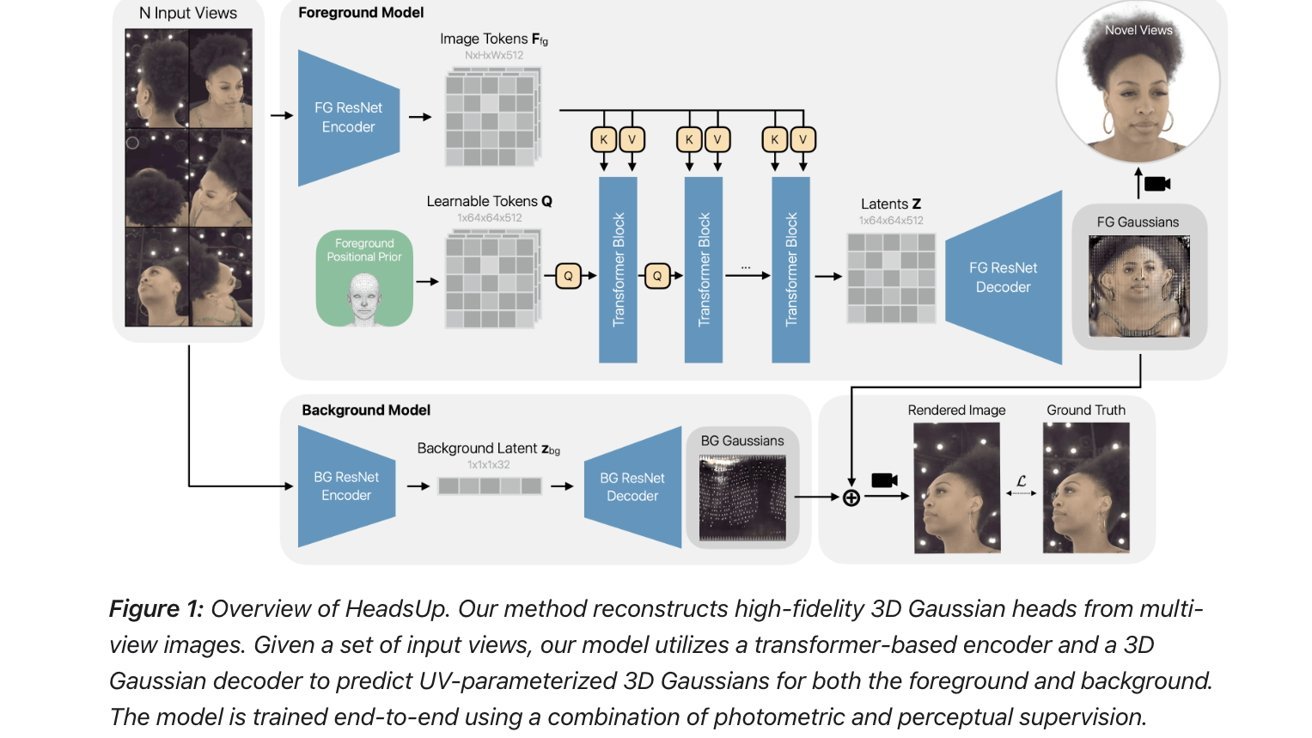
苹果AI研究团队探索如何用大模型从多视角捕捉生成3D头部模型。图片来源:Apple
他们开发了HeadsUp,这是一种可扩展的前馈方法,能从大规模多相机系统中重建高质量的3D高斯头部模型。
简单来说,论文探讨了如何把不同角度的头部图像转换成高斯球,再通过一系列编码器和解码器生成3D模型。
为了验证这个图像转3D模型的方法,他们用了一个内部数据集,包含超过1万名受试者,比现有的多视角人体头部数据集大一个数量级。这些3D头部模型还能用表情混合形状进行动画驱动。
总体上,HeadsUp达到了目前最好的重建质量,而且不用测试时优化就能泛化到新的人物身份。
实际应用方面,这项研究很可能跟Apple Vision Pro的Persona功能有关。苹果可能想进一步提升表情渲染效果,或者改进visionOS里脸部捕捉和渲染的质量。
另外也可能涉及硬件或舒适度相关的应用。之前开发头显时,苹果就为Vision Pro准备了各种不同的3D头部模型。
苹果会怎么利用这些研究成果,还得时间来回答。虽然下一代产品还要等等,但有一点很清楚:公司在AI和空间计算上完全没有退缩。
苹果将在2026年6月8日开幕的WWDC 2026上发布iOS 27以及其他操作系统更新。